Download raw (7.0 KB)
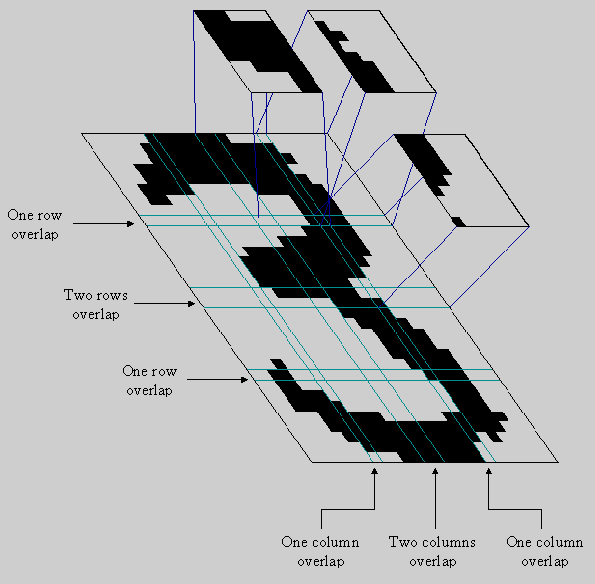
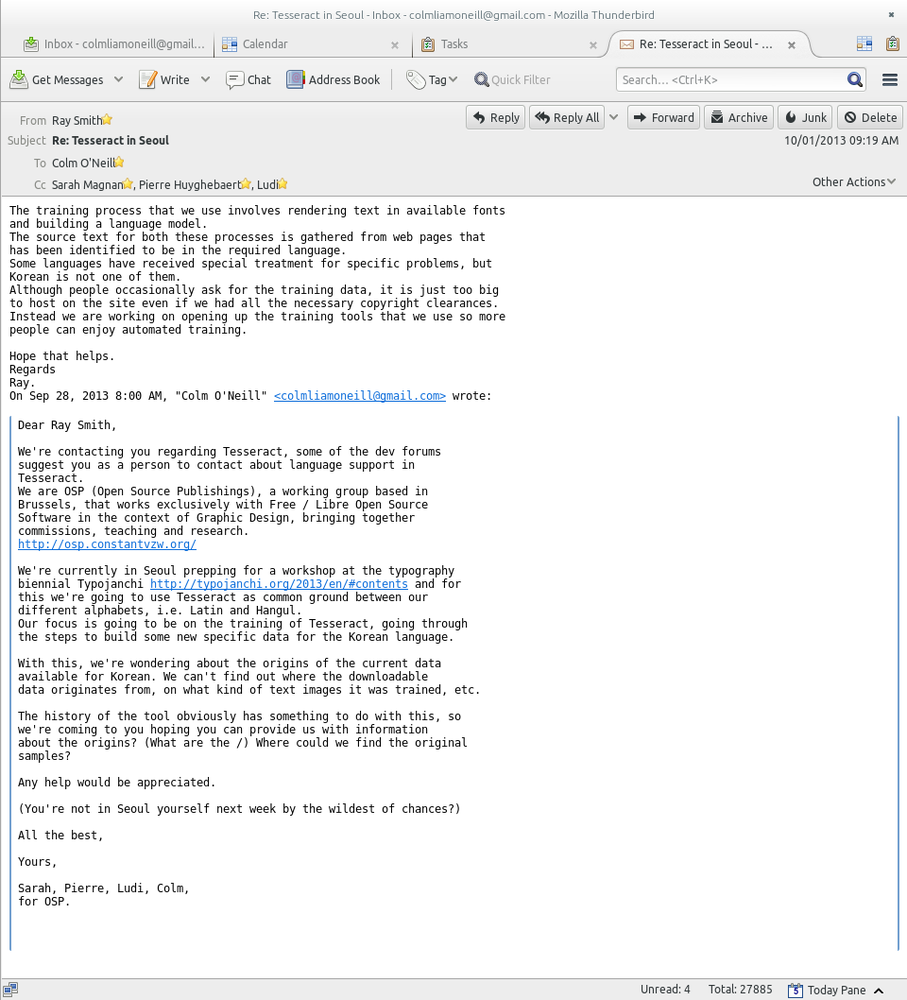
osp small text (related to our 4) workshop intitulé (long) explanation of the process dates mercis listes des outils ------------------------------------------- Fancy reading machines and androids from science-fiction fantasies are embodied in our modern lower-profile world as OCR software packages. OCR means Optical Character Recognition and it is software that can extract text from image files. One of these softwares, the free and open source Tesseract [1] is composed of two parts that we can study, thanks to its license. There is the engine itself, and the training data for a language [2] partly based on what Tesseract called 'prototypes'. We could compare this 'before the type' (proto-type) to the culture a lecturer progressively gathers from his first lesson going from a novice to a fully grown expert. By following the limits between the blank surfaces and the dark pixels of the shapes of letters, Tesseract compares its journey with previous ones, on images already followed in the past. It starts by learning patterns and specificities of languages, rhythms and irregularities. It goes on to recognise the body of a glyph, then it works out, bit by bit, if this glyph is a letter, form is a word, and eventually it makes out phrases. Like all of us, Tesseract learns typography in this same process, in a completely intertwined way, as sentences, script and eventually, language. [3] Tesseract follows rules by which it can make decisions. In a basic example from Latin script, if the software seems to be recognising something resembling to iii (three times the letter 'I'), specific rules kick in to suggest that it is most lightly the letter 'm' and not a triple consonant. Grammar and language coming in at a later stage, as it did for us, still following this unusual idea of teaching software to read. [4] The very specificities of typography and how each shape is drawn and could or couldn't be distinguised from another one arrives just after. As in the previous example the potential small parts that protrude from the I are more likely to be the arc of the m if the font is a serif one tha it is a sans serif one. This process becomes intertwined with the actual context: with time, the system becomes familiar, and extremely efficient with some specificities of a typeface. Its shape, its overall form and size now mean something. It would have to relearn an entirely new toolkit to be able to read a different typeface. With this, could the relations binding shapes to their meanings be noticed? At young, naive and early stages of deciphering writing systems, slowly working out the building blocks to a legible language, we wonder how synthetic constructions (like Hangul) compare to agglutinated ones (like Latin). More specifically, how do these methods influence OCR data? On a more contemporary note, it would be hard to deny how much screens and screen text technologies have influenced typography these days. All languages carry different meanings, different cultures with their characters. These gri(d)tty displays are no favour to typographic heritage, but they have brought on so much interesting conundrums. The rendering engine ttf autohint voluntarily distorts vector shapes of glyphs to optimise screen rendering [6]. In this workshop, we propose to carefully replay some of the processes the OCR system uses to reread typography from the departure point of any new learner, the one we all have known at first and mostly definitively forgotten by now... By patiently observing the various parameters at play when a letter is to be differentiated from another, the thin and variable line of separation between signification and shape, between letter and typography begins to reveal itself. Could the different parts of the letters that compose barebones of other letters be recreated in a kind of wild reverse engineered Metafont [5] paradigm, where all of the shapes of the glyph are defined with geometrical equations? We wonder how much we can learn from methods borrowed off OCR. By replaying its methods, but basing ourselves on some parameters only, not aiming for full comprehension, but basic knowledge of how our different sets of characters work retracing its first steps only? Would the outcome of this be enough to go on to understanding typographic subtleties, enabling a bridge between specificities in shape and specificities in language? Finally, if we know organisation in Hangul and Latin are different, and that they do work along with similar ideas, could we try to avoid the main caveats of forcing comparisons between each? Instead can we focus on the systems that the OCR-by-human must use to read both for rethinking deeper specificities between the two composition methods, between these two typographies, between these languages? 1. http://en.wikipedia.org/wiki/Tesseract_(software) 2. https://code.google.com/p/tesseract-ocr/ 3. http://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3 4. http://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3#The_last_file_(unicharambigs) 5. http://en.wikipedia.org/wiki/Metafont 6. http://www.freetype.org/ttfautohint/#samples --------------- workshop process ------------------------------------------ Sarah Magnan (BE/FR) Graphic designer, Sarah started to experiment in ERG (Brussels) possible links between graphic design and new media art. From links to links she became curious and interested by collaborative work, sharing matters on web, on print and more widely on archiving matters: which status to gives to archive, how to make it born or reborn, how to share it, show it, confront it. Pierre Huyghebaert (BE)http://www.speculoos.com Exploring several practices around graphic design, he currently drives the studio Speculoos. Pierre is interested in using free sofware to re-learn to work in other ways and collaboratively on cartography, type design, web interface, schematic illustration, book design and teaching these practices. Along with participating in OSP, he articulate residential spaces and narratives through the artists temporary alliance Potential Estate and develop collaborative and subjective mapping with Towards and others Brussels urban projects. Ludivine Loiseau (BE/FR)www.ludi.be Formed at the Ecole Estienne (Paris), Ludi relearned everything in Brussels. She immersed herself in the centre for graphical delicacies Speculoos and met the OSP group aboard a van on route to Poland in 2008. Ludi questions the contemporary role of typography and her practice is reflected in her courses at the Ecole de Recherche Graphic, where she is a lecturer in typography and free software. Ludi also works with Mathieu Gabiot on advancing the issue of licensing furniture objects, and supports an ephemeral publishing project, Le Calendrier. Colm O'Neill ------------------------ Tools ------------------------ This workshop was made possible with the following tools: Tesseract-ocr 3.02, Tesseract git, Inkscape, Libre Office, svn checkout -r 659 http://tesseract-ocr.googlecode.com/svn/trunk/ tesseract The booklet has been designed in Libre Office and Inkscape by the students. The the pdf pages were compiled through Podofo Impose.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}