Download raw (15.2 KB)
# -*- coding: utf-8 -*-
# Python imports
import datetime
import time
import urllib
from urlparse import urlparse
import HTMLParser
import json
import re
import os
# PyPi imports
import markdown
from py_etherpad import EtherpadLiteClient
import dateutil.parser
import pytz
# Framework imports
from django.shortcuts import render_to_response, get_object_or_404
from django.http import HttpResponse, HttpResponseRedirect
from django.template import RequestContext
from django.template.defaultfilters import slugify
from django.core.urlresolvers import reverse
from django.core.context_processors import csrf
from django.core.exceptions import PermissionDenied
from django.contrib.auth.decorators import login_required
from django.utils.translation import ugettext_lazy as _
# Django Apps import
from etherpadlite.models import *
from etherpadlite import forms
from etherpadlite import config
from django.contrib.sites.models import get_current_site
from relearn.management.commands.index import snif
# By default, the homepage is the pad called ‘start’ (props to DokuWiki!)
try:
from relearn.settings import HOME_PAD
except ImportError:
HOME_PAD = 'About.md'
try:
from relearn.settings import BACKUP_DIR
except ImportError:
BACKUP_DIR = None
"""
Set up an HTMLParser for the sole purpose of unescaping
Etherpad’s HTML entities.
cf http://fredericiana.com/2010/10/08/decoding-html-entities-to-text-in-python/
"""
h = HTMLParser.HTMLParser()
unescape = h.unescape
"""
Create a regex for our include template tag
"""
include_regex = re.compile("{%\s?include\s?\"([\w._-]+)\"\s?%}")
@login_required(login_url='/accounts/login')
def padCreate(request):
"""
Create a pad
"""
# normally the ‘pads’ context processor should have made sure that these objects exist:
author = PadAuthor.objects.get(user=request.user)
group = author.group.all()[0]
if request.method == 'POST': # Process the form
form = forms.PadCreate(request.POST)
if form.is_valid():
n = form.cleaned_data['name']
n = re.sub(r'\s+', u'_', n)
pad = Pad(
name=slugify(n)[:42], # This is the slug internally used by etherpad
display_slug=n, # This is the slug we get to change afterwards
display_name=n, # this is just for backwards compatibility
server=group.server,
group=group
)
pad.save()
return HttpResponseRedirect(reverse('pad-write', args=(pad.display_slug,) ))
else: # No form to process so create a fresh one
form = forms.PadCreate({'group': group.groupID})
con = {
'form': form,
'pk': group.pk,
'title': _('Create pad in %(grp)s') % {'grp': group.__unicode__()}
}
con.update(csrf(request))
return render_to_response(
'pad-create.html',
con,
context_instance=RequestContext(request)
)
@login_required(login_url='/accounts/login')
def pad(request, pk=None, slug=None): # pad_write
"""Create and session and display an embedded pad
"""
# Initialize some needed values
if slug:
pad = get_object_or_404(Pad, display_slug=slug)
else:
pad = get_object_or_404(Pad, pk=pk)
padLink = pad.server.url + 'p/' + pad.group.groupID + '$' + \
urllib.quote_plus(pad.name)
server = urlparse(pad.server.url)
author = PadAuthor.objects.get(user=request.user)
if author not in pad.group.authors.all():
response = render_to_response(
'pad.html',
{
'pad': pad,
'link': padLink,
'server': server,
'uname': author.user.__unicode__(),
'error': _('You are not allowed to view or edit this pad')
},
context_instance=RequestContext(request)
)
return response
# Create the session on the etherpad-lite side
expires = datetime.datetime.utcnow() + datetime.timedelta(
seconds=config.SESSION_LENGTH
)
epclient = EtherpadLiteClient(pad.server.apikey, pad.server.apiurl)
try:
result = epclient.createSession(
pad.group.groupID,
author.authorID,
time.mktime(expires.timetuple()).__str__()
)
except Exception, e:
response = render_to_response(
'pad.html',
{
'pad': pad,
'link': padLink,
'server': server,
'uname': author.user.__unicode__(),
'error': _('etherpad-lite session request returned:') +
' "' + e.reason + '"'
},
context_instance=RequestContext(request)
)
return response
# Set up the response
response = render_to_response(
'pad.html',
{
'pad': pad,
'link': padLink,
'server': server,
'uname': author.user.__unicode__(),
'error': False,
'mode' : 'write'
},
context_instance=RequestContext(request)
)
# Delete the existing session first
if ('padSessionID' in request.COOKIES):
if 'sessionID' in request.COOKIES.keys():
try:
epclient.deleteSession(request.COOKIES['sessionID'])
except ValueError:
response.delete_cookie('sessionID', server.hostname)
response.delete_cookie('padSessionID')
# Set the new session cookie for both the server and the local site
response.set_cookie(
'sessionID',
value=result['sessionID'],
expires=expires,
domain=server.hostname,
httponly=False
)
response.set_cookie(
'padSessionID',
value=result['sessionID'],
expires=expires,
httponly=False
)
return response
def xhtml(request, slug):
return pad_read(request, "r", slug + '.md')
def pad_read(request, mode="r", slug=None):
"""Read only pad
"""
# FIND OUT WHERE WE ARE,
# then get previous and next
try:
articles = json.load(open(os.path.join(BACKUP_DIR, 'index.json')))
except IOError:
articles = []
SITE = get_current_site(request)
href = "http://%s" % SITE.domain + request.path
prev = None
next = None
for i, article in enumerate(articles):
if article['href'] == href:
if i != 0: # The first is the most recent article, there is no newer
next = articles[i-1]
if i != len(articles) - 1:
prev = articles[i+1]
# Initialize some needed values
pad = get_object_or_404(Pad, display_slug=slug)
padID = pad.group.groupID + '$' + urllib.quote_plus(pad.name.replace('::', '_'))
epclient = EtherpadLiteClient(pad.server.apikey, pad.server.apiurl)
# Etherpad gives us authorIDs in the form ['a.5hBzfuNdqX6gQhgz', 'a.tLCCEnNVJ5aXkyVI']
# We link them to the Django users DjangoEtherpadLite created for us
authorIDs = epclient.listAuthorsOfPad(padID)['authorIDs']
authors = PadAuthor.objects.filter(authorID__in=authorIDs)
authorship_authors = []
for author in authors:
authorship_authors.append({ 'name' : author.user.first_name if author.user.first_name else author.user.username,
'class' : 'author' + author.authorID.replace('.','_') })
authorship_authors_json = json.dumps(authorship_authors, indent=2)
name, extension = os.path.splitext(slug)
meta = {}
if not extension:
# Etherpad has a quasi-WYSIWYG functionality.
# Though is not alwasy dependable
text = epclient.getHtml(padID)['html']
# Quick and dirty hack to allow HTML in pads
text = unescape(text)
else:
# If a pad is named something.css, something.html, something.md etcetera,
# we don’t want Etherpads automatically generated HTML, we want plain text.
text = epclient.getText(padID)['text']
if extension in ['.md', '.markdown']:
md = markdown.Markdown(extensions=['extra', 'meta', 'headerid(level=2)', 'attr_list', 'figcaption'])
text = md.convert(text)
try:
meta = md.Meta
except AttributeError: # Edge-case: this happens when the pad is completely empty
meta = None
# Convert the {% include %} tags into a form easily digestible by jquery
# {% include "example.html" %} -> <a id="include-example.html" class="include" href="/r/include-example.html">include-example.html</a>
def ret(matchobj):
return '<a id="include-%s" class="include pad-%s" href="%s">%s</a>' % (slugify(matchobj.group(1)), slugify(matchobj.group(1)), reverse('pad-read', args=("r", matchobj.group(1)) ), matchobj.group(1))
text = include_regex.sub(ret, text)
# Create namespaces from the url of the pad
# 'pedagogy::methodology' -> ['pedagogy', 'methodology']
namespaces = [p.rstrip('-') for p in pad.display_slug.split('::')]
meta_list = []
# One needs to set the ‘Static’ metadata to ‘Public’ for the page to be accessible to outside visitors
if not meta or not 'status' in meta or not meta['status'][0] or not meta['status'][0].lower() in ['public']:
if not request.user.is_authenticated():
pass #raise PermissionDenied
if meta and len(meta.keys()) > 0:
# The human-readable date is parsed so we can sort all the articles
if 'date' in meta:
meta['date_iso'] = []
meta['date_parsed'] = []
for date in meta['date']:
date_parsed = dateutil.parser.parse(date)
# If there is no timezone we assume it is in Brussels:
if not date_parsed.tzinfo:
date_parsed = pytz.timezone('Europe/Brussels').localize(date_parsed)
meta['date_parsed'].append(date_parsed)
meta['date_iso'].append( date_parsed.isoformat() )
meta_list = list(meta.iteritems())
tpl_params = { 'pad' : pad,
'meta' : meta, # to access by hash, like meta.author
'meta_list' : meta_list, # to access all meta info in a (key, value) list
'text' : text,
'prev_page' : prev,
'next_page' : next,
'mode' : mode,
'namespaces' : namespaces,
'authorship_authors_json' : authorship_authors_json,
'authors' : authors }
if not request.user.is_authenticated():
request.session.set_test_cookie()
tpl_params['next'] = reverse('pad-write', args=(slug,) )
if mode == "r":
return render_to_response("pad-read.html", tpl_params, context_instance = RequestContext(request))
elif mode == "s":
return render_to_response("pad-slide.html", tpl_params, context_instance = RequestContext(request))
elif mode == "p":
return render_to_response("pad-print.html", tpl_params, context_instance = RequestContext(request))
def home(request):
try:
articles = json.load(open(os.path.join(BACKUP_DIR, 'index.json')))
except IOError: # If there is no index.json generated, we go to the defined homepage
try:
Pad.objects.get(display_slug=HOME_PAD)
return pad_read(request, slug=HOME_PAD)
except Pad.DoesNotExist: # If there is no homepage defined we go to the login:
return HttpResponseRedirect(reverse('login'))
sort = 'date'
if 'sort' in request.GET:
sort = request.GET['sort']
hash = {}
for article in articles:
if sort in article:
if isinstance(article[sort], basestring):
subject = article[sort]
if not subject in hash:
hash[subject] = [article]
else:
hash[subject].append(article)
else:
for subject in article[sort]:
if not subject in hash:
hash[subject] = [article]
else:
hash[subject].append(article)
tpl_articles = []
for subject in sorted(hash.keys()):
# Add the articles sorted by date ascending:
tpl_articles.append({
'key' : subject,
'values': sorted(hash[subject], key=lambda a: a['date'] if 'date' in a else 0)
})
tpl_params = { 'articles': tpl_articles,
'sort': sort }
return render_to_response("home.html", tpl_params, context_instance = RequestContext(request))
@login_required(login_url='/accounts/login')
def publish(request):
tpl_params = {}
if request.method == 'POST':
tpl_params['published'] = True
tpl_params['message'] = snif()
else:
tpl_params['published'] = False
tpl_params['message'] = ""
return render_to_response("publish.html", tpl_params, context_instance = RequestContext(request))
def css(request):
try:
pad = Pad.objects.get(display_slug='screen.css')
padID = pad.group.groupID + '$' + urllib.quote_plus(pad.name.replace('::', '_'))
epclient = EtherpadLiteClient(pad.server.apikey, pad.server.apiurl)
return HttpResponse(epclient.getText(padID)['text'], mimetype="text/css")
except:
# If there is no pad called "css", loads a default css file
f = open('relearn/static/css/screen.css', 'r')
css = f.read()
f.close()
return HttpResponse(css, mimetype="text/css")
def cssprint(request):
try:
pad = Pad.objects.get(display_slug='laser.css')
padID = pad.group.groupID + '$' + urllib.quote_plus(pad.name.replace('::', '_'))
epclient = EtherpadLiteClient(pad.server.apikey, pad.server.apiurl)
return HttpResponse(epclient.getText(padID)['text'], mimetype="text/css")
except:
# If there is no pad called "css", loads a default css file
f = open('relearn/static/css/laser.css', 'r')
css = f.read()
f.close()
return HttpResponse(css, mimetype="text/css")
def offsetprint(request):
try:
pad = Pad.objects.get(display_slug='offset.css')
padID = pad.group.groupID + '$' + urllib.quote_plus(pad.name.replace('::', '_'))
epclient = EtherpadLiteClient(pad.server.apikey, pad.server.apiurl)
return HttpResponse(epclient.getText(padID)['text'], mimetype="text/css")
except:
# If there is no pad called "css", loads a default css file
f = open('relearn/static/css/offset.css', 'r')
css = f.read()
f.close()
return HttpResponse(css, mimetype="text/css")
def css_slide(request):
try:
pad = Pad.objects.get(display_slug='slidy.css')
padID = pad.group.groupID + '$' + urllib.quote_plus(pad.name.replace('::', '_'))
epclient = EtherpadLiteClient(pad.server.apikey, pad.server.apiurl)
return HttpResponse(epclient.getText(padID)['text'], mimetype="text/css")
except:
# If there is no pad called "css", loads a default css file
f = open('relearn/static/css/slidy.css', 'r')
css = f.read()
f.close()
return HttpResponse(css, mimetype="text/css")
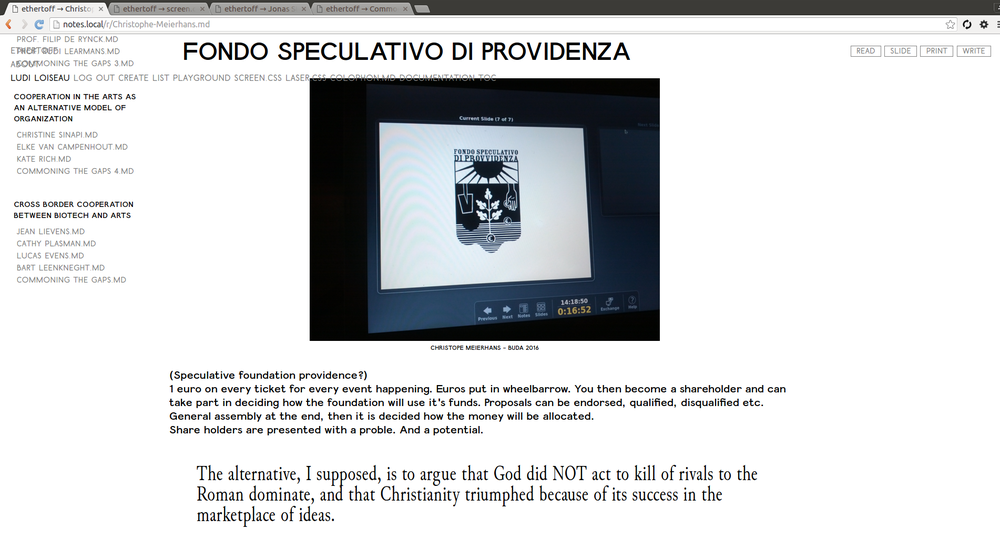
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}